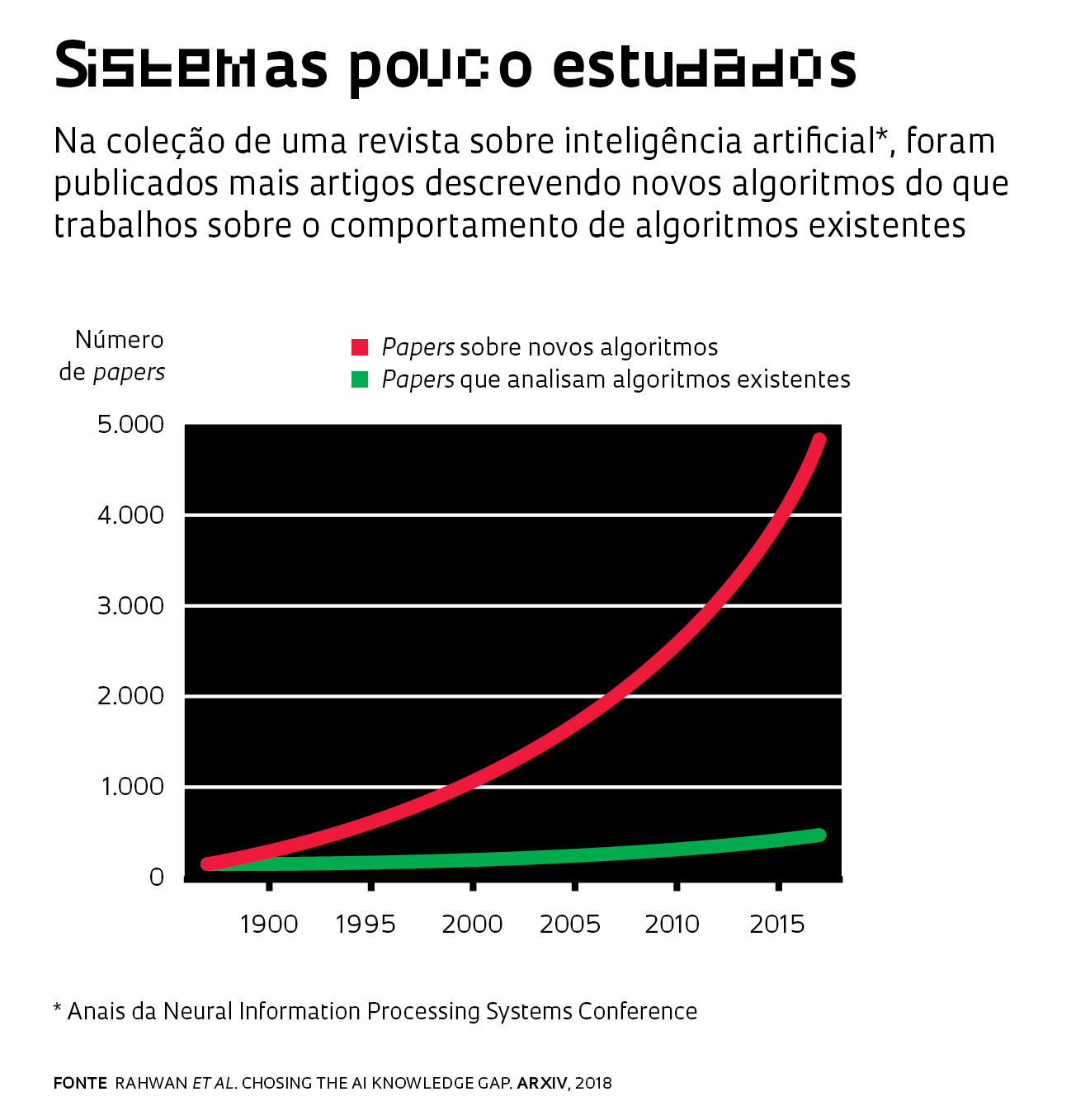
24/04/18 14:02:42
O mundo mediado por algoritmos

Imagem:

Os algoritmos estão em toda parte. Quando a bolsa sobe ou desce, eles geralmente estão envolvidos. Segundo dados divulgados em 2016 pelo Instituto de Pesquisa Econômica Aplicada (Ipea), robôs investidores programados para reagir instantaneamente ante determinadas situações são responsáveis por mais de 40% das decisões de compra e venda no mercado de ações no país – nos Estados Unidos, o percentual chegou a 70%. O sucesso de uma simples pesquisa no Google depende de uma dessas receitas escritas em linguagem de programação computacional, que é capaz de filtrar em segundos bilhões de páginas na web – a importância de uma página, definida por um algoritmo, baseia-se na quantidade e na boa procedência de links que remetem a ela. Na fronteira da pesquisa em engenharia automotiva, conjuntos de algoritmos utilizados por carros autônomos processam informações captadas por câmeras e sensores, tomando instantaneamente as decisões ao volante sem intervenção humana.
Embora influenciem até mesmo atividades cotidianas prosaicas, como a procura de atalhos no trânsito com a ajuda de aplicativos de celular, os algoritmos costumam ser vistos como objetos intangíveis pela população em geral – que sente seus efeitos, mas não conhece ou compreende seu formato e modo de ação. Um algoritmo nada mais é do que uma sequência de etapas para resolver um problema ou realizar uma tarefa de forma automática, quer ele tenha apenas uma dezena de linhas de programação ou milhões delas empilhadas em uma espécie de pergaminho virtual. “É o átomo de qualquer processo computacional”, define o cientista da computação Roberto Marcondes Cesar Junior, pesquisador do Instituto de Matemática e Estatística da Universidade de São Paulo (IME-USP).
Tome-se o exemplo da sequência de passos realizada pelo algoritmo do Facebook. A escolha do que vai aparecer no feed de notícias de um usuário depende, em primeiro lugar, do conjunto de postagens produzidas ou que circulam entre os amigos. Em linhas gerais, o algoritmo analisa essas informações, descarta posts denunciados como de conteúdo violento ou impróprio, os que pareçam spam ou os que tenham uma linguagem identificada como “caça-cliques”, com exageros de marketing. Por fim, o algoritmo atribui uma nota para cada uma das publicações com base no histórico da atividade do usuário, tentando supor o quanto ele seria suscetível a curtir ou compartilhar aquela informação. Recentemente, o algoritmo foi modificado para reduzir o alcance de publicações oriundas de sites de notícias.
A construção de um algoritmo segue três etapas (ver infográfico). A primeira consiste em identificar com precisão o problema a ser resolvido – e encontrar uma solução para ele. Nessa fase, o cientista da computação necessita da orientação de profissionais que entendam da tarefa a ser executada. Podem ser médicos, no caso de um algoritmo que analisa exames de imagem; sociólogos, se o objetivo for identificar padrões de violência em regiões de uma cidade; ou psicólogos e demógrafos na construção, por exemplo, de um aplicativo de paquera. “O desafio é mostrar que a solução do problema existe do ponto de vista prático, que não se trata de um problema de complexidade exponencial, aquele para o qual o tempo necessário para produzir uma resposta pode crescer exponencialmente, tornando-o impraticável”, explica o cientista da computação Jayme Szwarcfiter, pesquisador da Universidade Federal do Rio de Janeiro (UFRJ).
 A segunda etapa ainda não envolve operações matemáticas: consiste em descrever a sequência de passos no idioma corrente, para que todos possam compreender. Por último, essa descrição é traduzida para alguma linguagem de programação. Só assim o computador consegue entender os comandos – que podem ser ordens simples, operações matemáticas e até algoritmos dentro de algoritmos –, tudo em uma sequência lógica e precisa. É nesse momento que entram em cena os programadores, profissionais incumbidos de escrever os algoritmos ou trechos deles. A depender da complexidade da missão, equipes extensas de programadores trabalham em conjunto e dividem tarefas.
A segunda etapa ainda não envolve operações matemáticas: consiste em descrever a sequência de passos no idioma corrente, para que todos possam compreender. Por último, essa descrição é traduzida para alguma linguagem de programação. Só assim o computador consegue entender os comandos – que podem ser ordens simples, operações matemáticas e até algoritmos dentro de algoritmos –, tudo em uma sequência lógica e precisa. É nesse momento que entram em cena os programadores, profissionais incumbidos de escrever os algoritmos ou trechos deles. A depender da complexidade da missão, equipes extensas de programadores trabalham em conjunto e dividem tarefas.
Em sua origem, algoritmos são sistemas lógicos tão antigos quanto a matemática. “A expressão vem da latinização do nome do matemático e astrônomo árabe Mohamed al-Khwarizmi, que no século IX escreveu trabalhos de referência sobre álgebra”, explica a cientista da computação Cristina Gomes Fernandes, professora do IME-USP. Eles ganharam novos propósitos na segunda metade do século passado com o desenvolvimento dos computadores – por meio deles, foi possível criar rotinas para as máquinas trabalharem. A combinação de dois fatores explica por que suas aplicações no mundo real vêm se multiplicando e eles se tornaram a base do desenvolvimento de softwares complexos. O primeiro foi a ampliação da capacidade de processamento dos computadores, que aceleraram a velocidade da execução de tarefas complexas. E o segundo foi o advento do Big Data, o barateamento da coleta e do armazenamento de quantidades gigantescas de informações, que deram aos algoritmos a possibilidade de identificar padrões imperceptíveis ao olhar humano em atividades de todo tipo. A manufatura avançada ou Indústria 4.0, com sua promessa de ampliar a produtividade de linhas de produção, depende de algoritmos de inteligência artificial para monitorar plantas industriais em tempo real e tomar decisões sobre recomposição de estoques, logística e paradas de manutenção.
Um dos efeitos da disseminação dos algoritmos na computação foi o impulso à inteligência artificial, um campo de estudo criado na década de 1950 que desenvolve mecanismos capazes de simular o raciocínio humano. Com cálculos computacionais cada vez mais velozes e acervos de informação com os quais é possível fazer comparações estatísticas, as máquinas ganharam a capacidade de modificar seu funcionamento a partir de experiências acumuladas e melhorar seu desempenho, em um processo associativo que mimetiza a aprendizagem.
A capacidade de computadores vencerem humanos em jogos de tabuleiro mostra como esse campo tem evoluído. Em 1997, o supercomputador Deep Blue, da IBM, conseguiu pela primeira vez vencer o então campeão mundial de xadrez, o russo Gary Kasparov. Capaz de simular aproximadamente 200 milhões de posições do xadrez por segundo, a máquina antevia o comportamento do adversário várias jogadas à frente. Mas essa estratégia não funcionava em um jogo de origem chinesa, o Go, porque os lances possíveis eram numerosos demais para serem antecipados – o rol de possibilidades é maior do que a quantidade de átomos no universo. Pois, em março de 2016, a barreira do Go foi vencida: o programa AlphaGo, criado pela DeepMind, subsidiária do Google, conseguiu superar o campeão mundial do jogo, o sul-coreano Lee Sedol.
 Em vez de considerar milhões de possibilidades, o algoritmo do programa arrumou uma estratégia mais restrita. Foi abastecido com dados de partidas de Go disputadas entre os melhores competidores, fez uma análise estatística identificando as jogadas mais comuns e eficientes e passou a trabalhar com um conjunto pequeno de variáveis, logo vencendo os jogadores humanos. Mas o feito não parou aí. No ano passado, a DeepMind apresentou um novo programa, o AlphaGo Zero, que superou o AlphaGo. E dessa vez a máquina não aprendeu com seres humanos, mas apenas com a versão anterior do programa.
Em vez de considerar milhões de possibilidades, o algoritmo do programa arrumou uma estratégia mais restrita. Foi abastecido com dados de partidas de Go disputadas entre os melhores competidores, fez uma análise estatística identificando as jogadas mais comuns e eficientes e passou a trabalhar com um conjunto pequeno de variáveis, logo vencendo os jogadores humanos. Mas o feito não parou aí. No ano passado, a DeepMind apresentou um novo programa, o AlphaGo Zero, que superou o AlphaGo. E dessa vez a máquina não aprendeu com seres humanos, mas apenas com a versão anterior do programa.
As aplicações práticas desse tipo de tecnologia são cada vez mais frequentes. Algoritmos de inteligência artificial desenvolvidos pelo cientista da computação Anderson de Rezende Rocha, professor do Instituto de Computação da Universidade Estadual de Campinas (Unicamp), têm auxiliado investigações feitas pela Polícia Federal. Rocha especializou-se em criar ferramentas de computação forense e inteligência artificial capazes de detectar sutilezas em documentos digitais muitas vezes imperceptíveis a olho nu. “A tecnologia ajuda o perito, por exemplo, a confirmar se determinada foto ou vídeo relacionados a um crime são genuínos”, diz Rocha.
Um dos casos em que os algoritmos estão sendo utilizados é na automatização de investigações sobre pornografia infantil. Constantemente, os policiais apreendem grandes quantidades de fotos e vídeos no computador de suspeitos. Se existirem arquivos com pornografia infantil, o algoritmo ajuda a encontrá-los. “Expusemos o robô a horas de vídeos pornográficos da internet para extrair dados. Tivemos que ensinar a ele o que é pornografia”, conta Rocha. Depois, para que pudesse distinguir a presença de crianças, o algoritmo precisou “assistir” a conteúdos de pornografia infantil apreendidos. “Essa etapa foi realizada estritamente por técnicos da polícia. Nós da Unicamp não tivemos acesso a esse material”, salienta. Rocha conta que a análise dos arquivos era feita sem muita automação. “Ao tornar esse processo mais eficiente, os investigadores da Polícia Federal ganharam tempo e capacidade para analisar maiores quantidades de dados”.
Muitos cientistas da computação trabalham com propriedades matemáticas, teoremas e questões lógicas relacionadas a algoritmos, independentemente da perspectiva de aplicações imediatas. Em muitas situações que requerem algoritmos, os únicos algoritmos conhecidos são muito ineficientes, que não funcionam, na prática, com grandes massas de dados. Alguns exemplos disso, são a fatoração de inteiros em primos (com grande importância em criptografia), e a roteirização de um robô soldador por vários pontos de solda. Existe uma pequena esperança de que algoritmos eficientes venham a ser encontrados para esses problemas. A formulação precisa disso é a questão “P versus NP”, considerado, ao mesmo tempo, um dos maiores desafios da computação e da matemática.
 Embora exista mais programação do que ciência básica no desenvolvimento de boa parte dos algoritmos usados no cotidiano, avanços em conhecimento de fronteira são essenciais para que novas aplicações possam ser exploradas no futuro. Marcondes Cesar, da USP, coordena um projeto de visão computacional, um tipo de inteligência artificial que consegue extrair informações de imagens simulando o funcionamento da visão humana. Essa técnica está sendo incorporada em diversos setores, com destaque para a emissão de diagnósticos médicos. “A visão computacional permite detectar anomalias com mais precisão e avaliar sutilezas em imagens de ressonância magnética, por exemplo.”
Embora exista mais programação do que ciência básica no desenvolvimento de boa parte dos algoritmos usados no cotidiano, avanços em conhecimento de fronteira são essenciais para que novas aplicações possam ser exploradas no futuro. Marcondes Cesar, da USP, coordena um projeto de visão computacional, um tipo de inteligência artificial que consegue extrair informações de imagens simulando o funcionamento da visão humana. Essa técnica está sendo incorporada em diversos setores, com destaque para a emissão de diagnósticos médicos. “A visão computacional permite detectar anomalias com mais precisão e avaliar sutilezas em imagens de ressonância magnética, por exemplo.”
O projeto, uma parceria com a Faculdade de Medicina e o Instituto da Criança do Hospital das Clínicas da USP, busca criar um modelo matemático que permita fazer uma análise mais acurada do fígado e do cérebro de recém-nascidos. Em geral, a interpretação de imagens geradas por ressonância magnética baseia-se em modelos criados em outros países para homens adultos e brancos, o que pode gerar diagnósticos imprecisos em recém-nascidos. Mas, para que isso seja viável, é preciso resolver problemas teóricos. “Ainda não sabemos se conseguiremos obter um algoritmo cuja aplicação seja eficiente. Estamos ainda estudando propriedades com base na teoria dos grafos”, diz, referindo-se ao ramo da matemática que estuda as relações entre objetos de um determinado conjunto, associando-os por meio de estruturas chamadas grafos.
O impacto dos algoritmos é objeto de análise de outros campos do conhecimento. “Algoritmos já estão desempenhando um papel moderador. Google, Facebook e Amazon conquistaram um poder extraordinário sobre o que encontramos hoje no campo cultural”, avalia Ted Striphas, professor de história da cultura e da tecnologia na Universidade do Colorado, Estados Unidos e autor do livro Algorithmic culture (2015), que examina a influência dessas ferramentas. O antropólogo norte-americano Nick Seaver, pesquisador da Universidade Tufts, nos Estados Unidos, dedica-se atualmente a um projeto baseado em pesquisa etnográfica e entrevistas com criadores de algoritmos de recomendação de músicas em serviços de streaming. Seu interesse é compreender como esses sistemas são desenhados para atrair usuários e chamar a sua atenção, trabalhando na interface de áreas como aprendizado de máquina e publicidade on-line. “Os mecanismos que controlam a atenção e suas mediações técnicas tornaram-se objeto de grande preocupação. A formação de bolhas de interesse e de opinião, as fake news e a distração no campo político são atribuídas a tecnologias desenhadas para manipular a atenção dos usuários”, explica.
Sistemas de recomendação controlados por algoritmos tornaram-se peças-chave na indústria de entretenimento na internet. Em um artigo publicado em 2015 no periódico ACM Transactions on Management Information Systems, o engenheiro eletrônico mexicano Carlos Gomez-Uribe descreveu o funcionamento de conjuntos de algoritmos desenvolvidos pelo serviço de streaming Netflix que fazem rankings personalizados de séries e filmes condizentes com o perfil dos usuários. O desafio é levar o cliente a escolher um programa em menos de 90 segundos – depois desse tempo a tendência é frustrar-se e perder interesse. O sucesso do ranking valorizou o passe profissional de Gomez-Uribe, que em 2017 se tornou coordenador de algoritmos e de tecnologias de produtos da internet do Facebook.
A influência e o poder das grandes empresas da internet não dependem apenas da criatividade de seus programadores. Tem a ver, igualmente, com o acesso ao Big Data que elas acumularam e é processado por seus algoritmos, gerando informações valiosas. “O que impede outra empresa de desenvolver um aplicativo como o da Uber? Isso já foi feito. Mas os dados que a Uber dispõe sobre o trânsito e o comportamento dos usuários acumulados ao longo do tempo pertencem apenas à empresa e são valiosos”, diz Marcondes Cesar, da USP.
 O escândalo envolvendo o vazamento de dados de usuários do Facebook, que fez a empresa perder US$ 49 bilhões de seu valor no mês passado, revelou uma vulnerabilidade que se imaginava incomum – algoritmos utilizados pela empresa Cambridge Analytica conseguiram obter dados do comportamento de 50 milhões de usuários do Facebook e os utilizaram para orientar campanhas nas redes sociais pela saída do Reino Unido da União Europeia e em favor da candidatura de Donald Trump à presidência dos Estados Unidos, que acabaram vitoriosas. O caso do Facebook é exemplar dos desafios éticos gerados pela disseminação do uso de algoritmos, embora o vazamento e uso indevido dos dados sejam apenas uma parte do problema. A oferta de dados tornou-se tão importante na construção de algoritmos quanto o desafio de programá-lo. “Analisar as características dos dados ofertados é fundamental na hora de construir um algoritmo, porque descuidos nesse momento podem provocar vieses nos resultados”, afirma Marcondes Cesar.
O escândalo envolvendo o vazamento de dados de usuários do Facebook, que fez a empresa perder US$ 49 bilhões de seu valor no mês passado, revelou uma vulnerabilidade que se imaginava incomum – algoritmos utilizados pela empresa Cambridge Analytica conseguiram obter dados do comportamento de 50 milhões de usuários do Facebook e os utilizaram para orientar campanhas nas redes sociais pela saída do Reino Unido da União Europeia e em favor da candidatura de Donald Trump à presidência dos Estados Unidos, que acabaram vitoriosas. O caso do Facebook é exemplar dos desafios éticos gerados pela disseminação do uso de algoritmos, embora o vazamento e uso indevido dos dados sejam apenas uma parte do problema. A oferta de dados tornou-se tão importante na construção de algoritmos quanto o desafio de programá-lo. “Analisar as características dos dados ofertados é fundamental na hora de construir um algoritmo, porque descuidos nesse momento podem provocar vieses nos resultados”, afirma Marcondes Cesar.
Também é comum que, ao se balizarem por comportamentos humanos, os algoritmos reproduzam preconceitos. O Cloud Natural Language API, uma ferramenta criada pelo Google que revela a estrutura e o significado de textos por meio de aprendizado de máquina, desenvolveu tendências preconceituosas. Um teste feito pelo site norte-americano Motherboard mostrou que, ao analisar parágrafos de textos para determinar se eles apresentavam sentidos “positivos” ou “negativos”, o algoritmo classificou declarações do tipo “eu sou homossexual” e “eu sou uma mulher negra gay” como negativas. “Programadores que criam algoritmos inteligentes precisam estar conscientes de que o trabalho deles tem implicações sociais e políticas”, diz Nick Seaver, da Universidade Tufts. Alguns cursos de graduação e pós-graduação em ciência da computação já oferecem disciplinas que abordam ética computacional. É o caso da USP, no Brasil, e da Universidade Harvard e do Instituto de Tecnologia de Massachusetts (MIT), nos Estados Unidos.
Outro debate em ebulição relaciona-se à transparência de algoritmos avançados. Ocorre que detalhes do desenvolvimento dessas ferramentas frequentemente são mantidos em segredo por seus criadores. Em outros casos, a complexidade do código é tamanha que um observador não consegue entender como ele produz uma decisão e quais são suas implicações. Sistemas opacos ao escrutínio externo ganham o apelido de “algoritmos caixa-preta”. A discussão ganhou impulso com a investigação sobre uma ferramenta utilizada experimentalmente no judiciário norte-americano, o Compas (Correctional Offender Management Profiling for Alternative Sanctions) – seu algoritmo sugere a pena do condenado e ainda vaticina sobre a possibilidade de reincidência. O estudo, feito em 2016 pela organização ProPublica revelou que, ao passarem pelo crivo do Compas, acusados negros têm 77% mais probabilidade de serem classificados como possíveis reincidentes do que acusados brancos. A Northpointe, empresa privada que criou o algoritmo, recusou-se a divulgar o código do Compas. “Algoritmos de dimensão pública não devem ser criados nem desenvolvidos sem a participação dos gestores e administradores públicos, pois não são neutros”, destaca Sérgio Amadeu da Silveira, pesquisador do Centro de Engenharia, Modelagem e Ciências Sociais Aplicadas da Universidade Federal do ABC (UFABC).
Em 2017, Kate Crawford, líder de pesquisa da Microsoft Research, e Meredith Whittaker, diretora do Open Research, ligado ao Google, fundaram o AI Now Institute, organização dedicada a investigar o impacto da inteligência artificial na sociedade. Com sede na Universidade de Nova York, Estados Unidos, a instituição investe em uma abordagem que integra análises de cientistas da computação, advogados, sociólogos e economistas. Em outubro, divulgou um relatório com orientações sobre o uso de algoritmos de inteligência artificial. Uma das recomendações é que órgãos públicos responsáveis por setores como justiça, saúde, assistência social e educação evitem usar algoritmos cujos modelos não sejam bem conhecidos. O documento recomenda que os algoritmos caixa-preta passem por auditorias públicas e testes de validação como forma de instituir mecanismos de correção quando necessário.
Liberar seres humanos de atividades repetitivas é outro presságio dos algoritmos de inteligência artificial – e o debate sobre as implicações dos softwares inteligentes no mercado de trabalho ganha corpo. O relatório “O futuro do emprego”, publicado em 2013 pelos economistas Carl Frey e Michael Osborne, da Oxford Martin School, avaliou que algoritmos sofisticados podem substituir 140 milhões de profissionais que atuam em atividades intelectuais em todo o mundo. O documento menciona exemplos como a crescente automatização das decisões tomadas no mercado financeiro e até mesmo o impacto no trabalho dos engenheiros de software – por meio do aprendizado de máquina, a programação pode ser aperfeiçoada e acelerada com o auxílio de algoritmos. “Atividades intelectuais procedurais, que envolvem repetição de padrões, como traduzir documentos, têm uma possibilidade enorme de serem executadas por algoritmos”, avalia Sérgio Amadeu, da UFABC. O debate sobre os efeitos colaterais da inteligência artificial é necessário, avalia Marcondes Cesar, da USP, mas por enquanto está longe de se contrapor às notáveis contribuições dos algoritmos na solução de problemas de todo tipo.

Expressões faciais
A Hoobox Robotics, empresa fundada em 2016 por pesquisadores da Unicamp, desenvolveu um sistema para ser instalado em qualquer cadeira de rodas motorizada e permite que pessoas tetraplégicas possam controlar o veículo utilizando apenas as expressões faciais. O algoritmo presente no software, que leva o nome de Wheelie, traduz até 11 expressões faciais, como um sorriso e uma sobrancelha levantada, em comandos para seguir em frente, retroceder e virar à direita ou à esquerda. O programa está sendo testado em 39 pacientes nos Estados Unidos, onde a empresa mantém uma unidade de pesquisa no laboratório da Johnson&Johnson, em Houston. O sistema utiliza uma câmera 3D que capta dezenas de pontos no rosto.
“O usuário pode configurar um comando para cada expressão. Um sorriso, por exemplo, pode mover a cadeira para frente, um beijo, para trás”, esclarece o cientista da computação Paulo Gurgel Pinheiro, diretor da Hoobox. Para assimilar as principais expressões, o algoritmo do Wheelie foi abastecido com um conjunto de dados faciais de 103 motoristas de caminhão. “Firmamos uma parceria com uma companhia de transporte para instalar câmeras em caminhões e registrar as impressões faciais dos voluntários ao longo de três meses”, explica Gurgel.
Para identificar parasitas
Aprimorar o diagnóstico de parasitoses usando visão computacional é o objetivo de um projeto executado no IME-USP em colaboração com o Laboratory of Image Data Science (LIDS) da Unicamp. O cientista da computação Marcelo Finger, do IME, está testando um algoritmo capaz de identificar parasitas processando imagens de lâminas com fezes de pacientes. “Já conseguimos identificar 15 parasitas em humanos e alguns em animais, como bois, gatos e cachorros”, conta. Hoje, o diagnóstico é obtido pela análise das fezes em microscópio. “O profissional geralmente consegue avaliar umas seis lâminas por vez.
A intenção é automatizar esse processo”, afirma Finger. Parece simples, mas, sabendo que os algoritmos buscam identificar padrões, qualquer ruído pode se tornar um obstáculo para os pesquisadores. “Uma coisa é o algoritmo conseguir identificar o parasita na foto de um livro, outra é fazer o mesmo a partir de uma imagem em que o parasita está rodeado de sujeira”, ressalva o pesquisador.

O peso do boi
Há algoritmos talhados para ajudar pecuaristas. A Projeta Sistemas, startup localizada em Vitória (ES), criou um sistema computacional chamado “Olho do Dono”, que se baseia em imagens 3D para estimar o peso de um boi. “O processo de pesagem dos animais é muito custoso e demorado, implicando deslocamento dos bois, que podem ficar estressados e até perder peso”, explica o cientista da computação Pedro Henrique Coutinho, diretor da Projeta. O software foi desenvolvido com base em técnicas de visão computacional associando às imagens dos bois feitas por câmeras seus respectivos pesos. Para isso, foi necessário formar uma base de dados robusta. “Acompanhamos pesagens de gado em fazendas em todo o Brasil. A partir do registro de milhares de imagens, pudemos desenvolver nosso algoritmo”, diz Coutinho. O software começou a ser desenvolvido em 2015 e começará a ser comercializado em setembro.
Animais perdidos
O CrowdPet é um aplicativo para smartphone que identifica animais perdidos criado pela SciPet, empresa originada na Unicamp. Por meio de um algoritmo, o sistema cruza dados referentes a fotos de animais perdidos cadastradas por seus donos e imagens de animais avistados nas ruas por voluntários.“O aplicativo permite a correspondência entre as duas imagens por meio de métodos de reconhecimento visual e faz o rastreamento por geolocalização do local onde foi feita a foto do animal perdido”, diz Fabio Rogério Piva, cientista da computação e diretor da SciPet. O Centro de Controle de Zoonoses do município paulista de Vinhedo começou a utilizar o aplicativo no ano passado para cadastrar animais durante campanhas de bem-estar animal. A SciPet desenvolveu um protótipo capaz de diferenciar, com 99% de acerto, cães e gatos de outros animais.

